Последната актуализация на този раздел е от
2021 година.
6.3.1
Опашки и буфериране на машинни команди. Управление на буферите. Команди
за преход и предсказване на преходите
От направения
анализ и представените в предидущия пункт констатации и изводи тук ще обърнем
внимание на логическата структура и на алгоритмите за управление на три вида
FIFO-буфери:
·
Буфер за регулярно организирани
данни ;
·
Буфер за нерегулярно
организирани данни ;
·
Буфер за машинни команди.
А) Буфер за регулярно организирани данни
Ще
започнем с най-обикновения буфер – този, който буферира регулярно
(последователно) трансфериращи се данни. Характерно за тези данни е, че те имат един и същи формат и не се
съпровождат с никакви идентификатори. Най-разбираемите източници на данни с
такова регулярно и последователно следване са например аналого-цифровите
преобразователи или някакъв вид носители на информация, генериращи и
трансфериращи голям обем данни. Тези буфери функционират като обикновени
FIFO-памети, често наричани опашки. За тях е характерно,
че са безадресни запомнящи устройства, чиято инициализация се постига до
момента на използването им, при това в логически възли стоящи вън от тях. Така
например, ако буферът е зареден с 4[KiB] данни, които следва да се изхвърлят в оперативната памет
в последователни клетки, защото редът на подредбата на данните не трябва да се
променя, то това може да се постигне при предварително зададен начален адрес и
неговото автоматично модифициране след всяка операция запис в паметта. Типичен
пример за последния коментар е обменът, управляван чрез DMA каналите. С
казаното искаме да поясним, че задаването на началния адрес на приемната област
в оперативната памет и неговото модифициране нямат никакво отношение в случая
към логическата структура на буфера.
Ние
вече изяснихме достатъчно подробно логическата структура и функциониране на
този тип запомнящи устройства (вижте глава 4, §4.3).
Ще изтъкнем отново само това, че този тип буфер предава данни между системи с
различна производителност без да има отношение към тяхното местоположение.
Б) Буфер за нерегулярно организирани данни
Ще
поясним, че за разлика от последователната подредба на данните, която се имаше
предвид в предидущата буква, тук ще разгледаме случая на буфериране на непоследователно
адресирани (т.е. нерегулярни) данни. Като имаме предвид, че едната
подсистема в системата на буфера е оперативната памет (или някакво друго
адресируемо запомнящо устройство), казаното ще се отнася както до FIFO буфери
за четене така и до FIFO буфери за запис. При това положение споменатата
нерегулярна организация на данните следва да се разбира и в двата случая във
връзка с местоположението им в адресното пространство на оперативната памет.
Следователно при операция “четене” оперативната памет се отъждествява с подсистема
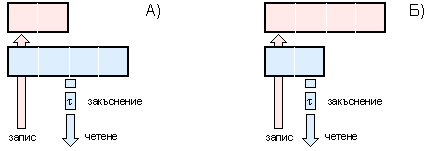
№1, а при операция “запис” – с подсистема №2 (вижте следващата фигура 6.3.1.1).
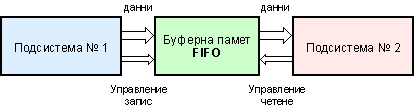
Фиг. 6.3.1.1. Място на ОП в системата с FIFO буфер
1. Нека си представим, че в буферната памет
следва да се подготвят (и да очакват използването си) данните, които са
операнди в една последователност от няколко машинни команди – част от текущо
изпълняваната машинна програма. Тези операнди се намират в най-общия случай в
различни и несъседни клетки на оперативната памет. Адресите на тези клетки се
съдържат в последователните машинни команди, които реализират последователния
изчислителен процес, откъдето следва, че операндите ще бъдат подредени
(подготвени) в буферната памет именно в този ред и ще очакват своето участие в
съответните операции. Веднъж подредени в буферната памет, редът на тяхната
употреба се оказва регулярен. Нека обърнем внимание и на още едно
обстоятелство, а именно, че веднъж консумирани от буфера (за целите на
изчисленията), операндите стават ненужни (в общия случай).
Изводът,
който се налага след осмисляне на казаното по-горе, може да бъде само един –
при операция “четене” няма нищо особено в използването на FIFO буфера, което
да налага някакви изменения в логическата му структура. Това означава, че
описаните в 4-та глава на тази книга структури на FIFO памети са напълно
приложими в разглеждания тук случай.
2. Нека сега разгледаме буферирането на
получаваните при изчислителния процес резултати. Имайки предвид конвейерната
организация на изпълнение на последователността от машинни команди, излизащите
от конвейерите резултати следва да се записват незабавно. Темпът на
конвейера е такъв, че естественото решение на тази задача е временно записване
на данните във FIFO опашка (буфер). В тази опашка готовите резултати очакват
подходящия момент, когато ще могат да бъдат записани в оперативната памет. В
нашите обяснения тук този момент е изключително важен, защото трябва да
поясним, че местоположението на всяка дума в буфера следва да бъде записана в
свой собствен адрес, и което е още по-важно – тази операция по същество
предстои да бъде изпълнена, за което освен с данните, трябва да разполагаме и с
адресите. Или с други думи - всички данни записани в буфера трябва да се съпровождат от съответните
адреси, по които следва да бъдат разпределени (припомняме нерегулярно) в
оперативната памет. Нека, за да бъдем окончателно разбрани, да се изразим
метафорично по следния начин – най-характерното за тази опашка от очакващи
своето пътуване “пътници” е, че те се придвижват в нея заедно със своите “билети”,
на които е написано за къде пътуват. Съпровождащата данните информация може
да се възприема като идентифицираща ги и нейното наличие, съответно подреждане
и съответно синхронно придвижване, ни дава да разберем, че логическата
структура на този буфер следва да бъде различна от тази, описана в точка 1.
Читателят трябва добре да осмисли, че това се дължи на операция “запис”, т.е.
че разглежданият буфер е за запис.
В съответствие с казаното по-горе, представата ни за буфера за запис е структура от две паралелни и синхронни (съответни) опашки, изразена на фигура 6.3.1.2. Както се вижда неговата структура не единна и е трудно да бъде разглеждана само и единствено съвместно. Структурните елементи на буфера за запис могат да бъдат включени в състава на други устройства. Така например в устройството за управление на паметта се съдържат: списък (опашка) за извличанията от паметта; опашка с адресите за запис; таблици за право и обратно преобразуване на адресите и др.
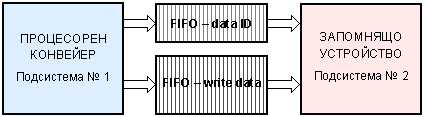
Фиг. 6.3.1.2.
FIFO буфер за запис
(обща представа при нерегулярни данни)
Казаното прави FIFO буфера за запис
по-сложен и изискващ повече внимание, отколкото буфера за четене. Сложността на
структурата на FIFO буфера за нерегулярни данни го прави практически неприложим.
Всички случаи, в които на практика се реализира буфер за запис, по една или
друга причина се свеждат в реализацията си към регулярната му структура.
Типичен пример е обменът с оперативната памет. Тук, въпреки, че адресируемата
единица е един байт, обменът се извършва в единици, наречени пакети –
цели 32 байта (в порции по 8 байта на 4 последователни такта). Тези 32 байта са
с последователни адреси и цялата структура е регулярна, т.е. тя има един
начален адрес.
В) Буфериране на кеш-линии
В техническото описание на реалните съвременни процесори е отделено не малко внимание на така наречения “write buffer”, още няколко думи за който ще кажем и ние. По същество точно тези буфери могат да се разбират като клетки с голяма дължина (8 байта, т.е. 256 бита), тъй като те подсигуряват движението на кеш-линиите от кеш паметта към оперативната памет и обратно – от оперативната памет към кеш паметта. За да си изясним ролята на тези буфери нека си представим следната задача: имаме две чашки – едната с кафе, другата с чай. Необходимо е да разменим тяхното съдържание. Читателят вероятно разбира, че тази задача не може да се реши без допълнителна чашка, която в нашата терминология ще играе ролята на споменатия буфер.
Тук в
този пункт, във връзка с горните, а така също и с някои от следващите по-долу
обяснения, дължим извинение на уважаемия читател, защото бяха използвани и ще
бъдат използвани, все още недефинирани понятия. Това разбира се ще направим
малко по-късно.
Фирмата Intel например, представя мястото на този буфер по следния начин (фигура 6.3.1.3):
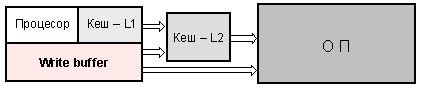
Фиг. 6.3.1.3. Място на FIFO буфер (според Intel)
Както се вижда, буферът е разположен успоредно на кеш-линиите в кеш паметта. Intel твърди, че за избягване на неуспешно обръщение (разбираме опит за запис) и загуба на тактове, процесорът помества данните в буфера за запис, откъдето при освобождаване на шината и/или на кеш-контролера, данните се изпращат в кеш паметта от първо (второ) ниво или в оперативната памет. Тук държим да обърне внимание на читателя върху терминологията (изразяването) – твърдението, че това прави процесорът е несъстоятелно, защото какво всъщност е процесор? Читателят следва добре да разбита, че тук става дума за управлението на една специфична и скрита от потребителя структура, а тя се управлява апаратно от вградените в нея управляващи автомати, които в по-коректните текстове се наричат кеш-контролери. След всичко казано ние ще си представяме по-нататък буферите за запис и за зареждане като дълги клетки, които подсигуряват движението на данните от цели кеш-линии, съответно в двете посоки – към/от кеш паметта на първо ниво. Въпросът ще бъде допълнително конкретизиран тук в следващите раздели.
Въпреки наименованието си, се твърди още, че
буферът за запис е достъпен освен за запис още и за четене. При това, четенето
от буфера, се осъществявало поне на един такт по-бързо, отколкото от кеша L1. С
други думи резултатът от изпълнението на поредната машинна команда е достъпен
за четене веднага след попадането му в буфера. Тази възможност конструкторите
наричат “изпреварващ
запис” (Store-Forwarding).
Твърди се, че тази възможност е особено полезна, когато броят на четенията
значително надхвърля броя на записванията. Ако честотата на неуспешните
записвания не превишава скоростта, с която буферът се разтоварва, то
наказателните тактове (penalty) (закъснения) при четене не възникват и
ефективната скорост на командата за запис е 1 такт. От тук може да се създаде
неправилното впечатление, че колкото повече буфери има, толкова по-голяма е
възможната пределна честота на неуспешните записвания. Всъщност максималната
честота на неуспешните записвания се определя единствено от скоростта (и
от политиката, т.е. от алгоритъма) за разтоварване на буфера. В частност,
буферите за запис в процесорите на AMD винаги се разтоварват в кеш
паметта на първо ниво. Така скоростта, с която се опразва един 32(64) байтов
буфер в най-добрия случай е 1 такт, а достъпът на процесора до данните в кеша
на първо ниво е незабавен.
За разлика от AMD, процесорите на Intel
най-често разтоварват буфера за запис в кеш паметта на второ ниво (вижте
по-горе фигура 6.3.1.3). С това вероятно се е целяло да се избегнат
“замърсяващите” кеш паметта на първо ниво записвания, което повишава нейната
ефективност. От друга страна обаче процесорът не е в състояние да понесе висока
интензивност на неуспешните записвания. В следствие на тази политика за
разтоварване на буфера за запис се появява известно изкривяване на стратегията
за запис в кеша на първо ниво. Въпреки, че формално тази кеш памет е
реализирана по стратегията “Write Back”, фактически тя работи по
стратегията “Write True”, тъй като неуспешното записване довежда
до непосредствено обновяване на кеш паметта на по-високото ниво, без зареждане
на модифицираните данни в кеша.
Следва да обърнем внимание на четенето след запис. По този повод фирмата AMD говори за “голям кръг на кръвообръщение” (изчислително устройство ® блок за запис ® кеш памет ® блок за четене ® изчислително устройство) и за “малък кръг на кръвообръщение” (изчислително устройство ® буфер за запис ® изчислително устройство). Естествено този подход за четене е ефективен ако се четат тези данни, които са били записани преди това. В противен случай следват “наказания” (penalty), в резултат на които бързодействието на програмата рязко спада. Четенето от буфера за запис в процесорите на Intel следва да се осъществява с огромно внимание, тъй като току що записаните данни могат във всеки момент да бъдат разтоварени в кеш паметта на второ ниво, което рязко увеличава времето за достъп до тях.
Ще се спрем малко по-подробно на “наказанията” при функционирането на буфера за запис. Нека си представим, че записваме в буфера клетки 0, 1, 2 и 3, а след това четем съдържанието на клетки 2, 3, 4 и 5 (вижте по-долу фигура 6.3.1.4-А). Лесно се съобразява, че клетките 4 и 5 не се съдържат в буфера и за да бъдат доставени следва да се извърши обръщение към кеш паметта. В същото време в кеша липсват и клетки 2 и 3, тъй като те все още не са напуснали буфера. Не е известно как точно се постъпва в тази ситуация. Възможно е едната част от заявените клетки да се чете от буфера, а другата част от кеша, след което двете части да се “обединяват”. По-вероятно е всички искани данни да се вземат от кеша, което предполага предварителното “разтоварване” на буфера в кеш паметта. Както и да е организиран достъпа обаче всичко това изисква допълнителни тактове.
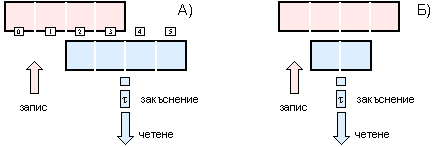
Фиг. 6.3.1.4. Възникване на закъснения при припокриване на областите за четене и запис
Освен описаната ситуация са възможни и други, при които се натрупват тактове закъснение. Ако предположим, че данни изцяло се намират в буфера, но адресите на клетките за четене не съвпадат с адресите на записаните, отново се натрупват тактове закъснение заради необходимите в случая преобразования, свързани с “изрязване” на излишните битове от записания резултат (вижте по-горе фигура 6.3.1.4-Б). Следващата ситуация, която е пояснена на следващата фигура, предполага че адресите на клетките съвпадат, но последните имат различна разрядност, което е отново причина за загуба на тактове. И това е логично, защото когато дължината на записваната клетка е по-малка от тази на четената, то само част търсените данни попадат в буфера (вижте фигура 6.3.1.5-А) а всичко останало се съдържа в кеша, т.е. ситуацията се свежда към по-горе описаната. Природата на закъснението при запис на клетка с по-голяма разрядност (фигура 6.3.1.5-Б) е по-труда за разбиране. Въпреки, че данните се извличат непосредствено от буфера, отсичането на излишните битове изисква някакво време (поне един такт)… Това твърдение е справедливо и при няколко къси записа припокривани от последващо дълго четене.
Фиг. 6.3.1.5. Възникване на закъснения при несъответствие в разрядността на данните
В резултат на току що казаното може да се формулира следното правило: четенето на данни непосредствено след техния запис следва да има същия стартов адрес и в същото време не по-голяма, а точно същата разрядност. От тук следва препоръката да не се работи със смесени формати на данните, като е препоръчително уеднаквяване към възможно по-късите.
Следващият
нюанс в алгоритъма за управление на буфера за запис се отнася до предявения
адрес. При четене, проверявайки буфера за наличие на данните, управляващият
автомат не анализира всички разряди на адреса, а само онези, които “отговарят”
за избора на конкретната кеш-линия в кеш паметта от първо ниво. От тук следва,
че ако адресите на записваните (четените) клетки, са кратни на размера на
кеш-банката (който може да определим като разделим размера на кеша на неговата
асоциативност) настъпва дезорганизация, като в резултат не може да се вземе
решение коя точно порция данни да бъде извлечена. Така възниква принудително
закъснение (при различните модели процесори от 6 до 10 такта), докато
“едноименните” клетки се разтоварят от буфера в кеша на първо ниво.
Конструкторите твърдят, че ако размерът на обработвания блок данни не превишава
размера на кеша, то опитът да се прочетат данни, липсващи в буфера за запис,
води минимум до 5 кратно снижение на производителността.
Освен
всичко казано до момента, на буфера за запис е възложена и задачата за подреждане
на записите. Задачата е свързана с това, че CISC машинните команди (Complex
Instruction Set Computer) се декомпозират при изпълнението си в
последователност от микрокоманди, които от своя страна също се буферират,
откъдето подхождат за последователно изпълнение в RISC-ядрото на процесора.
Редът за изпълнението им обаче е не винаги оптимален от гледна точка на ядрото,
в резултат на което възниква задачата за подреждането им. Обърнете внимание
обаче, че разместването на реда за изпълнение на операциите четене/запис може
да доведе до неправилна работа на програмата! Като пример нека се замислим
какво би станало при следните 2 операции:
А := (a) ; // четене съдържанието на клетка с адрес a - стойност на А //
a := В ; // запис
на резултата В в клетка с адрес a //
ако записът завърши по-рано от четенето? Обърнете внимание, че употребените адреси са едни и същи.
А дали това е възможно? И още как! Нека допуснем, че устройството за четене е все още заето с обработката на предходната машинна команда и командата А := (a) е принудена търпеливо да изчака своя ред, когато в същото време командата a := В заема бездействащото устройство за запис. В резултат на тази реална несинхронност променливата А ще получи стойността на В, а първоначалното съдържание на клетката a ще бъде безвъзвратно загубено!
Разбира се за да се отстрани тази несинхронност, устройството за запис би могло да бъде задържано за известно време, но това не би могло да бъде наречено решение, способстващо производителността. Изходът от тази неприятна ситуация е във временното съхраняване на записващите се данни не в кеш паметта (основната памет), а в един междинен буфер. За да не се задръства архитектурата на микроядрото с въвеждането на още един буфер, конструкторите са решили да се използват все същите буфери за запис. При което стратегията за разтоварване на буфера гарантира, че записаните в него данни ще го напуснат едва когато завършат всички предхождащи команди. Така буферизацията на записите води до съкращаване броя на обръщенията към паметта, тъй като ако една и съща клетка се е записвала няколко пъти, то в паметта (в кеша) попада само последният резултат.
В младшите модели на процесорите на Intel се съдържат два буфера за запис (write buffer) – по един за всеки от конвейерите U и V. В процесорите Pentium MMX те стават четири, а в Pentium-II са вече 12 на брой. Започвайки от този модел, във всички следващи модели тези буфери се наричат вече “складиращи” (Store Buffers). Като се има предвид, че обема на всеки буфер е 32 байта, то могат да се съхраняват до 384 байта (384=32.12), или още, това са 96 на брой 32-битови думи. Този значителен обем данни може да стои в буферите в случай, че се получи неуспешен опит за запис в кеш паметта. Разбира се, крайният случай на изцяло запълнени буфери, разтоварващи се директно в основната памет, довежда до възможно най-голямата загуба на тактове от закъснение. От тук произлиза препоръката за редуване на операциите запис с изчислителни операции, с което се осигурява необходимото време за разтоварване на буферите.
Описаните по-горе особености на буфера за запис не са единствените. За повече подробности отправяме читателя към специализираната литература на отделните фирми производителки. Припомняме на читателя, че тук за нас не е важен въпросът колко на брой са FIFO буферите в даден модел процесор, а задачите, които те решават. От там нататък ние се интересуваме от тяхната логическа структура и алгоритъм за управление.
Отчитайки тези особености на буферната памет, за които се говореше по-горе, много автори формулират различни препоръки към системните и приложните програмисти, целящи някаква оптимизация на своите програмни кодове. Някои от тези препоръки бяха формулирани по-горе като естествени изводи. Разбира се тази тематика излиза извън нашите интереси и няма да бъде осветлявана тук. Ще изкажем само мнението, че лошо избраните типове на данните, неоптималните алгоритмични решения и тяхната безотговорна програмна реализация тотално “зацапват” красотата на конструкторските решения за хардуера, карайки го да работи както житейски се казва - “преливайки от пусто в празно”. Ето защо считаме, че отговорностите на програмиста, държащ в ръцете си “Бижуто”, за което говорим, са огромни!
Г) Буфериране на машинни команди
Тук ще се спрем на едно от най-съществените буферирания в съвременните процесори, чиято съвкупност от задачи е една от най-комплицираните. Задачите, с които е натоварена тази част от структура на процесора, са така много и така различни, че тя излиза от представата ни за обикновен буфер. Алгоритъмът за управлението му е един от най-сложните, тъй като в него се фокусират всички съвременни подходи за повишаване на производителността на процесора, ето защо неговата реализация на практика се постига чрез множество самостоятелни устройства.
Първото съображение, което следва да изтъкнем, е конвейерната организация за изпълнение на машинните команди. Към настоящия момент структурата на процесорите е изключително усложнена и тенденцията това да продължава е трайна. Въпреки това, че операционната им част вече е мултифункционална и на пазара реално се предлагат процесори с няколко ядра, всяко от които съдържа по няколко паралелни конвейера, цялата тази апаратура се “захранва” от единствения поток последователно излизащи от оперативната памет машинни команди на програмата. Колкото повече такива паралелно работещи устройства има в процесора, толкова по-голяма става необходимостта от извлечени и подготвени за изпълнение команди и данни.
Второто съображение се отнася до дълбокото ешелониране на буферизацията. Имаме предвид, че между конвейерите в операционната част на процесора и оперативната памет има няколко нива различни кеш памети и опашки.
При анализа на информационния поток, който процесорът трябва да обслужва, вече бяха посочени някои особености, които определят както структурата на буфера, така и мястото му в нея, връзките му с други елементи и алгоритмите за управление. Така например, може да се отбележи, че последователността от машинни команди най-често се извлича от последователни адреси, което се дължи на метода на естественото адресиране. В този смисъл, потокът от команди към операционната част на процесора се буферира чрез организацията FIFO. Що се отнася до данните, които обработват командите, най-подходяща се явява асоциативната организация на буфера. На практика обаче конструкторите прилагат различни комбинации от двата вида организация.
Тук ще се спрем най-вече на цялостния ход на буферирането, на възникващите проблемни ситуации и където е възможно ще изясняваме структурите на устройствата за тяхното разрешаване.
Процесът
на запълване на буферната памет започва с началното зареждане на програмния
брояч и стартирането на първата програма. Вече беше пояснена целта на
предварително извличане (напомпване) на машинните команди. Ако извличаната
последователност от машинни команди е съставена от команди от групата на
основните, т.е. машинни команди, които предават безусловно
управлението на следващата по ред команда, намираща се в клетка със следващия
по ред адрес според програмния брояч, това означава, че за изпълнение в
операционната част на процесора, се зарежда линеен
алгоритмичен участък от програмата.
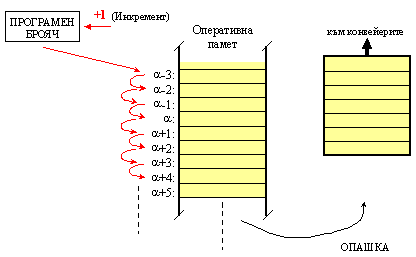
Фиг. 6.3.1.6. Схема за буфериране при команда за безусловен преход (БП)
Тази част от програмата не
създава никакви проблеми при своето “навлизане” в конвейерите. Ако тя е
достатъчно дълга, операционната част ще я “поглъща” и изпълнява от едната
страна, а от другата страна тя ще продължава да се зарежда, което като реален
ход на изчислителния процес е в пълно съответствие с последователния текст на
програмата. Ситуацията съответства до голяма степен на изобразеното на фигура
6.3.1.1.
Но,
както обикновено казваме, за съжаление, тази идилична ситуация не продължава
дълго. Объркването настъпва при среща на машинна команда от групата за
управление на прехода. Читателят вероятно добре разбира, че предварителното
извличане на машинните команди от последователни адреси не представлява реалния
ход на изчислителния процес. Реалният ход на програмата, или с други думи –
последователността от реално изпълняващите се машинни команди, съвсем не
протича в съответствие с техния последователен ред в клетките на оперативната
памет. Ходът на изчислителния процес зависи от реално изпълняващите се
алгоритмични преходи и в частност от машинните команди за управление на
преходите. Това означава, че предварителното
извличане на командите трябва да се извършва в съответствие с реалния ход на
програмата, а не с техния последователен ред на запис в паметта. От
тук следва изводът, че извличането на машинните команди следва да бъде
съпроводено с техния предварителен анализ.
Целта на предварителния анализ на всяка машинна команда е да се разпознае
нейната принадлежност към групата за управление на прехода.
Възможностите са две – ако тя не е от тази група това означава, че в следващите последователни адреси се съдържат най-вероятните за изпълнение команди. Тогава извлечената командата се записва в буфера (в опашката от вече извлечени и подготвени за изпълнение машинни команди), а съдържанието на програмния брояч се увеличава (модифицира).
Ако
извлечената машинна команда се окаже команда за безусловен преход, тя не се записва в
буфера. Машинната команда за безусловен преход всъщност променя рязко
последователността от изпълняващи се команди, като посочва друга начална точка,
чрез адреса за преход, който се съдържа в нея. В този смисъл изпълнението на тази машинна команда
може да бъде осъществено още по време на нейния предварителен анализ, без тя да
достига операционната част на процесора. Според метода за адресиране, указан в
командата, адресиращото устройство формира адреса за преход и го записва в
програмния брояч. С това завършва изпълнението на тази команда. По-нататък
процесът на “напомпване” продължава, но вече по новото съдържание на програмния
брояч. При това, последователността от подготвени за изпълнение команди ще се
окаже за конвейерите в операционната част на процесора, съвсем естествена. На
фигура 6.3.1.7 е показано съдържанието на буфера в сравнение с това на
оперативната памет. Вижда се, че двата линейни участъка (по адреси a и по
адреси d ) са конкатенирани в буфера, в който командата за безусловен преход не
се съдържа.
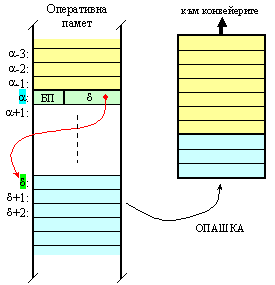
Фиг. 6.3.1.7. Схема за буфериране при команда за безусловен преход (БП)
В някои
съвременни процесори, с цел оптимизиране на конвейерите и минимизиране на
“празните” тактове в тях, конструкторите приемат да зареждат в опашката и командите
за преход, в това число и тези за преход към подпрограма и връщане от
подпрограма. Присъствието и движението на командата за преход в конвейера е
необходимо за прилагане на така наречената техника на “задържания” или
още на “отложения” преход. Тъй като тази техника се отнася до
управлението на конвейера и няма отношение към алгоритмите за предварително
извличане на командите, няма да бъде коментирана тук.
В
случай, че анализираната машинна команда се окаже команда за условен преход, за
разлика от предидущия случай, тя се записва в буфера, но без да може да се
изпълни. Проблемът е в това, че докато не бъде изпълнена стоящата преди нея
в опашката машинна команда, ходът на изчислителния процес е неизвестен. Тук ще припомним на читателя, че
всяка машинна команда, която по някакъв начин преработва данни, формира нови
стойности на признаците на резултата, получен от нея, които се използват именно
от последващи команди за условен преход. А възможностите за последващия ход на
изчислителния процес са две – или преход към следващия по ред адрес, или преход
към съвършено различен адрес, вписан в самата команда за управление на прехода.
Като
имаме предвид, че подготвените в опашката команди продължават да се придвижват
към непрекъснато работещите конвейери, другият край на опашката ще започне да
се опразва и спешно следва да се вземе решение как да продължи процесът на
извличане на команди. По отношение на буфера ситуацията с двата възможни клона
на командата за условен преход са илюстрирани на следващата фигура 6.3.1.8.
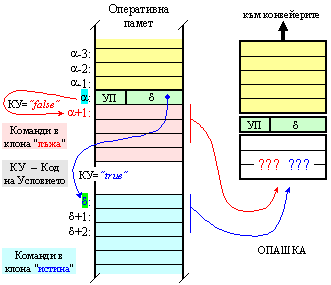
Фиг. 6.3.1.8. Въпросът за избор при буфериране след команда за условен преход (УП)
Възможни са няколко конструктивни решения за горе формулираната задача:
·
Временно блокиране на буфера до
фактическото изпълнение на условния преход ;
·
Организиране на конкурентни
опашки (опашки и за двете разклонения) ;
·
Извличане чрез предсказване на
прехода.
Временно блокиране на буфера
Най-тривиалното и евтино решение е първото. След разпознаване на команда за условен преход, записването на нови команди в буфера се блокира. С хода на изчислителния процес командата за условен преход се придвижва последователно към изхода на опашката, подхождайки и очаквайки своето изпълнение. Изпълнението на команди от този вид е свързано с проверка на стойността на определено условие (КУ), от което зависи и фактическо определяне на новото съдържанието на програмния брояч. Ако това условие не е изпълнено (КУ=0), съдържанието на програмния брояч остава непроменено. Ако условието е изпълнено (КУ=1), според съдържанието на командата, се формира адресът за преход, който се зарежда като ново съдържание на програмния брояч. Към момента на изпълнение на командата за условен преход обаче буферът се оказва напълно изпразнен, тъй като всички команди, съдържали се в него преди нея, са били вече изпълнени, а операция запис в буфера е била блокирана. След определяне обаче на новото съдържание на програмния брояч, блокировката на буфера се отменя и извличането се възобновява.
Основният
недостатък на това решение се съдържа във факта, че в момента, когато от
опашката в конвейера бъде заредена и последната изпълнима команда,
непосредствено предхождаща командата за условен преход, в продължение на
няколко такта, в резултат на които от конвейера слиза резултатът, необходим за
реализация на условния преход, в него за изпълнение не се зареждат нови команди. В резултат
конвейерът за изпълнение на машинни команди се оказва напълно “изпразнен”. В
същото състояние се оказва и буферът за команди. Така следващото достигане на
нормалното (пълното) захранване на конвейера става с много голямо закъснение.
За конвейера така образувалата се ситуация наричахме “мехурче".
Описаното
функциониране е достатъчно за да се разбере, че процедурите за запълване и
изпразване на буфера са взаимно свързани и следва да се управляват от едно общо
устройство. Освен това добре трябва да се разбира, че съдържанието на
програмния брояч в даден момент не е пряко свързано с изпълняващите се в
конвейерите машинни команди. Изложените тук обяснения читателят задължително
трябва да свърже с общата организация за функциониране на процесора, изложена в
глава 5 на тази книга.
Организиране на
конкурентни опашки
Ясно е, че за
отстраняване на описания по-горе недостатък, следва да се прибегне до
усложняване на управляващия алгоритъм. Едно от практикуваните решения,
предполага извличане на машинни команди и от двата клона на условния преход (и
от клон "false" и от клон 'true'). За целта
се реализират две опашки. В основната опашка се извлича следващата по ред
команда, стояща след командата за условен преход, т.е. по клона “false”.
Това извличане е по естествения ред на адресите, т.е. по съдържанието на
програмния брояч. Едновременно с това в адресиращото устройство на
допълнителната опашка се подготвя адресът за преход, указан от командата за
условен преход. В следващия такт се извлича командата по този адрес. По този
начин началната команда от алтернативния клон (клонът “true”) на
разклонението в програмата, се оказва подготвен в непосредствена близост до
операционната част на процесора. Съхраняването на тази команда до момента,
когато вероятно може да бъде заредена в конвейера, се осъществява в
допълнителния буфер. През това време, според структурата на оперативната памет,
предварителното извличане може да продължи в основния буфер или и в двата
буфера едновременно.
При
достигане изхода на опашката условната команда за преход блокира зареждането на
конвейерите до излизане на резултата на предхождащата я команда. По признаците
на този резултат се решава въпросът за алгоритмичното разклонение и следва
захранване на конвейерите с команди от съответния буфер. Ако условието за
преход е “false”, това са команди от основния буфер, в противен случай –
от допълнителния.
Специално
трябва да подчертаем отличието на тази ситуация от описаната в предидущата. И
тук конвейерът се изпразва след блокирането му, но след избора на преход,
захранването му с команди става веднага, тъй като те са вече подготвени.
Буферите
могат да сменят ролите си. Ако условната команда избере прехода “true”,
конвейерът ще се захрани с команди от допълнителния буфер, предварително
извлечени от оперативната памет. Това обаче ще го превърне в основен. Тогава
неговият конкурент ще трябва да играе ролята на допълнителен. Последният ще
бъде изчистен от съдържанието си, за да може при необходимост да приеме
машинните команди в клона на алгоритмичния преход “true” на следващата
команда за условен преход.
Структурата
на допълнителния буфер, алгоритъмът за неговото управление, обемът му, както и
смяната на ролите между двата конкурентни буфера, могат да имат различни
апаратно-технически решения. Основното достойнство на описаното решение обаче
се състои в това, че то способства за намаляване на задръжките при
функционирането на операционната част при нейната конвейерна организация.
Алгоритъмът
за управление на извличането в две паралелни опашки при буфериране на машинните
команди обаче среща затруднение когато командите за условен преход са с висока
честота в изпълняваната програма. Неприятната ситуация се състои в това, че по
време на предварителния анализ на текущо извлечената команда, последната може
да се окаже за условен преход. Ако в същото време, преди това заредената в
основния буфер команда за условен преход, все още не достигнала неговия изход,
ново приетата команда за условен преход не може да бъде “обслужена” по същия
начин. Ако искаме да приложим и за нея същия алгоритъм за управление на буфера
това означава реализация на нови две опашки и значително усложняване на
управляващия алгоритъм. Естествено, реализациите в това направление, не са
разумни. Ако все пак такава ситуация възникне, изходът е в блокиране на
изпреварващото извличане на команди в съответния буфер. Ако изчислителният
процес продължи в клона, където последно е извлечена команда за условен преход,
при нейното изпълнение буферната система ще се окаже в същата ситуация, в която
се оказва преди това описаната система. С други думи, това е ситуацията с
максимално закъснение в захранването на конвейерите.
Цикъл в областта
на буферираните команди
Тук ще се спрем на една особена ситуация, която се създава от някои алгоритмични преходи, най-общо определени като преход “назад”. Става дума за алгоритмични структури от тип цикъл. При анализа на тази структура възниква идея за по-ефективна работа на командния буфер. Идеята се състои във възможността да се избегне многократното пълнене на буфера (с едни и същи команди), ако в него вече се съдържат машинните команди от тялото на цикъла. Организацията на цикъл обикновено се осъществява чрез преход към по-малък адрес, а това означава, че ако дължината на този преход не е по-голяма от обема на буфера, то командата от входната точка на цикъла се намира в буфера и не е необходимо да се извлича повторно от основната памет.
Откриването
и използуването на тази ситуация е един естествен метод за повишаване на
ефективността на командния буфер. За целта, в управляващата схема на буфера за
команди трябва да се добавят средства за разпознаване и използуване на подобни
ситуации.
Критерият
за откриване на това дали командата, която трябва да получи управлението, се
намира в буфера (при затваряне на цикъл), или не, се съдържа в отношението
между дължината на прехода (измерен в брой адресируеми единици) и обема на
буфера. Ако това отношение е в полза на обема на буфера, то командата, която
трябва да получи управлението, вече се намира в буфера - това е командата във входната точка на цикъла. За да се
пристъпи към нейното изпълнение, съдържанието на адресния регистър за четене в
буфера трябва да се намали със същата стойност, с която би се намалило
съдържанието на програмния брояч, при осъществяване на адресния преход в
оперативната памет.
Всички
необходими за тази цел проверки се осъществяват особено лесно в случаите на
относително адресиране на командите за управление на прехода, които в тези
случаи съдържат в адресната си част отместването. Отместването е именно израз
на дължината на прехода в брой адресируеми единици и може да се използува
непосредствено за модифициране на съдържанието на адресния регистър за четене в
буфера. Тъй като най-често отместването е число със знак, изобразено в
допълнителен код, то по неговия знак лесно може да се установи посоката на
прехода - напред, към по-големите, или
назад, към по-малките адреси. Дължината на прехода (относно обема на буфера) може
да се оцени лесно по наличието или отсъствието на група от незначещи цифри в
старшата част на кода, изобразяващ отместването. Естествено, в случай, че
цикълът се затваря в рамките на буфера, операция запис в буфера следва да се
блокира, т.е. докато не се изпълни условието за край на цикъла, проверявано от
съответната команда за условен преход.
В
случая, когато схемата за управление на буфера ще следи и за наличие на
циклически преходи, то тя се модифицира във връзка с новите елементи в
алгоритъма за управление на операциите в буфера. Особено лесно се обяснява
управлението, когато буферът има кръгова структура с два адресни указателя (вижте фигура 4.3.1). Новите елементи се отнасят до
следното: след като в резултат на предварителния анализ на извлечената от
оперативната памет машинна команда се установи, че тя е за преход и стане ясно,
че продължението на програмата би нарушило запълването на буфера с
последователни команди (линеен участък), се блокира операция запис в буфера.
Участъкът от програмата, който вече се намира в буфера, се изпълнява до края,
след което двата адресни регистъра се нулират и запълването на буфера започва
от неговата първа клетка (адрес 00...0). При такъв начин на запълване се
получава така, че преди да се запълни изцяло адресното пространство на буфера с
команди, адресният регистър за запис съдържа число, показващо фактическата
дължина на записания линеен участък, а адресният регистър за четене съдържа
номера на текущо изпълняваната команда!
След записа на извлечената от оперативната памет команда в буфера се прави предварителен анализ на същата и ако се окаже, че тя е от групата на командите за управление на прехода, по-нататъшното запълване на буфера се блокира.
Изпълнението
на командата за преход (да не забравяме, че той е условен) може да се осъществи
по един от следните начини:
1. В случай, че преходът (напред или назад) е извън записания в буфера линеен
участък, двата адресни регистъра се нулират, а блокировката на операция запис
се отменя. Признаците по които се разпознава прехода назад, извън записания в
буфера линеен участък, са:
а) Когато
дължината на прехода е по-голяма от обема на буфера ;
б) Когато след изваждане на дължината на прехода (отместването) от съдържанието на адресния регистър за четене се получи отрицателен знак.
2. В случай, че преходът е назад, при това не е извън пределите на намиращия
се в буфера линеен участък, и при условие, че това е преход за ново повторение
на тялото на цикъла, блокировката на операция запис се запазва.
За да има възможност в буфера да се съхраняват и изпълняват вложени цикли, може да се добави още една проверка.
3. В случай, че условният преход назад не се осъществи (при преждевременен
изход от вътрешния цикъл), се проверява дали двата адресни регистъра имат едно
и също съдържание. Ако съвпадението е налице, това означава изход от външния
цикъл, при което блокировката за запис се отменя. Ако няма съвпадение, това
означава ново завъртане по външния цикъл, а оттам и по вътрешния. В този случай
блокировката на операция запис в буфера се запазва.
На
практика обаче системата от машинни команди дори на най-обикновените процесори
има променлив формат. В условията на командна система с променлив
формат управлението на командния буфер допълнително се усложнява. Усложнението
се отнася до предварителния анализ на командата във входния регистър на буфера,
което се състои в това, че положението на кода на операцията (КОП) в този
регистър не е фиксирано. По тази причина местоположението на КОП на следващата
команда трябва да се определя чрез използване на дължината на предхождащата я
команда. Ето защо, предварителен анализ на командата във входния регистър на
буфера в този случай не се извършва. Запълването на буфера продължава (дори
поредно извлечената команда да е за управление на прехода) с извличане на
последователно следващите в основната памет команди.
В момента на изпълнение на машинната команда за преход, ситуацията в буфера може да бъде следната: при преход назад, в буфера се съдържат само команди, след командата за преход. По тази причина, при преход назад, излизането извън съдържащият се в буфера участък от програмата, създава затруднения свързани с това, че буферът може да е частично запълнен или изцяло запълнен, при което адресният брояч за запис се е нулирал.
Измененията в управляващият алгоритъм са следните:
1. От адресният брояч за четене се изважда съдържанието на адресния брояч за
запис, т.е. чрез изваждането се нулира допълнителният най-старши разряд на адресния
брояч за четене. По този начин се определя броят на клетките в буфера,
съдържащи "изпомпеният" от оперативната памет последователен участък
на програмата, който предхожда командата за преход (преход назад).
2. От получената разлика, изчислена по описания по-горе начин, се изважда
зададеното в командата за преход отместване на адреса. Ако новата разлика е
отрицателно число, това означава, че преходът излиза извън съдържащият се в
буфера участък от програмата. В този случай, така както и в случая, когато
буферът работи с постоянен формат на командите, адресните броячи се нулират.
3. Ако получената в пункт 2 разлика е положително число, това означава, че
преходът, който трябва да се изпълни, е осъществим в рамките на буфера. Но
съдържанието на адресния брояч за четене се различава от адреса на клетката в
буфера, която трябва да получи управлението. За да се възстанови необходимият
адрес, към съдържанието на адресния брояч за четене се прибавя съдържанието на
адресния брояч за запис. Читателят не бива да забравя, че буферът е кръгов и
описаните операции се извършват фактически по модула на брояча, т.е. без
отчитане на преноса.
В случай, че извършваният преход е напред, или в случай на не състоял се преход (поради неизпълнено условие за преход), се изпълняват същите действия, които бяха определени за буфер, работещ с постоянен формат на командите.
С
цел да се избягнат сложните обработки, описани по-горе, в съвременните
процесори се прилага така нареченото изравняване
на командите, при което те се освобождават от допълнителната информация чрез
нейната незабавна употреба още на етапа предварителен анализ, при което добиват
еднакъв формат. Същността на изравняването на кода и на данните ще поясним тук по-късно в раздел 6.3.2.3 на тази книга. Той се пояснява още и в
книга
[4].
В съвременни условия благодарение на големите възможности на интегралните технологии, за реализация стават възможни и най-сложните алгоритми за управление на буферната памет за команди.
Извличане чрез
предсказване на прехода
Проблемът с
условните преходи се състои в това, че те са причина за появата на задръжки в
изчислителния процес. Задръжките, както вече пояснихме, се дължат на
неравномерното захранване на конвейерите в операционната част на процесора. В
борбата с тези задръжки, към настоящия момент, конструкторите масово прилагат
принципа “познал – спечелил”, т.е.
прилагат се различни технически решения, с които се цели предварително
определяне (с висока степен на сигурност) на реалното разклонение в условния
преход. Ако има възможност, разклонението да бъде предсказано със сигурност
по-голяма от 50%, то тези технически решения имат смисъл. Смисълът се състои в
това, че при тези решения, вместо да се приложи подходът на “грубата сила”,
който вече описахме под наименованието конкурентни опашки, ще се
преследва същия ефект, но с по-малко апаратни разходи.
Нека
сега приемем, че буферът не се блокира при среща на команда за условен преход и
продължава да се зарежда с команди например, по естествения ред на адресите,
т.е. в буфера попада участъкът от програмата, стоящ в разклонението “false”
след типична командата за условен преход. Може би тук е полезно да припомним,
че при команди за условен преход, клонът “false“ се адресира от
програмния брояч, а клонът “true" се адресира от самата команда. Ако изборът да се извлекат командите в клона
“false” се окаже правилен, от гледна точка на реалния ход на програмата,
то те ще попаднат в конвейерите незабавно и изпълнението им ще бъде без
закъснение. Ако обаче този избор се окаже неправилен и потребителската програма
се насочва в разклонението “true”, тогава извлечените в буфера команди
ще се окажат ненужни. Буферът ще трябва да бъде изчистен и процесът на
извличане ще следва да бъде възобновен от адреса за преход, пренесен в
програмния брояч от адресната част на командата за условен преход. В този
случай обаче изпълнението на програмата няма да бъде по-бавно от първия вариант
на управление – управление с блокировка на извличането. С други думи, при този
алгоритъм, времето на престой при блокировка на буфера, се заменя с изпомпване
на избраното разклонение. Загуби при това няма, а ползите са налице. Ако
предположим, че клоновете “false” и “true” в една програма са
равновероятни, то можем да твърдим, че описаното тук управление на буфера води
до поне 50% ускоряване на условните преходи. Това е доказателство, че търсенето
на алгоритми с предсказване на прехода, е актуална задача.
В
случай, че решим да не се уповаваме на случайния избор и се доверим на
своеобразно чувство за предполагане на разклонението, вероятността да спечелим
би била по-голяма от 50%. В тази връзка, ако се направи класификация на
възможностите за предугаждане (предсказване) на преходите, тя би изглеждала
така:
1.
Статически алгоритми:
·
Командите се буферират винаги по
клона “false”, т.е. не се предполага преход ;
·
Командите се буферират винаги по
клона “true”, т.е. предполага се преход във всички случаи ;
·
Преходът се предполага въз
основа на анализ на кода на операцията ;
2.
Динамически алгоритми:
·
Преходът се предполага според
състоянието на един или повече превключвателя ;
·
Преходът се предполага според
състоянието на таблица, съхраняваща предисторията на преходите.
Алгоритмите,
наречени статически, не използват информация за хода на изчислителния
процес при напомпването на буфера. Предварителното извличане се повлиява едва
след фактическото изпълнение на командата за условен преход. В този смисъл
първите два подхода не се различават съществено. Ако някой от тях, по някаква
случайност наистина съответствува на реалния ход на програмата, то той би
повишил нейната производителност. Съществуват научни изследвания, които са си
поставяли за цел да оценят статистически вероятността на разклоненията “false”
и “true”. Резултатите (макар и не в голяма степен) са в полза на прехода
по клона “true”. Все пак изборът на един от двата подхода зависи
съществено и от други фактори, като например от структурната организация на
оперативната памет. Ако статистическото предимство бъде взето предвид, очаква
се повишаване на производителността. Съществува обаче вероятност, загубата на
време при неправилно предсказване да се окаже толкова голяма, че
статистическата полза да бъде “изядена”. Този ефект се дължи на това, че в
единия случай извличането се осъществява в естествения ред на адресите, а в
другия случай по адреса за преход е възможно да няма информация. Ако последното
се случи, настъпва много голямо закъснение, тъй като процесът по доставка на
тази информация в оперативната памет е много дълъг. В тези последни изречения
става дума за събития, които могат да настъпят в условията на така наречената
“виртуална памет” – специално структуриране и организация на паметта, за което
тепърва предстои да говорим. Както читателят разбира, тук отново изпадаме в
ситуацията, когато в нашите обяснения използваме изпреварваща информация, за
което следва да се извиним.
Третият
подход за реализация на избора на разклонението за извличане, се реализира въз
основа на анализа на кода на операцията на командата за условен преход.
Съществуват научни изследвания, според които всяка команда за условен преход
има характерно за нея статистическо поведение. Ако то бъде отчетено, процесът
на предварително извличане ще реализира ползи в над 75% от случаите. Тези
твърдения не са безпочвени. Достатъчно е да си припомним, че в алгоритмичната
структура цикъл условният преход към входната му точка се изпълнява многократно
по-голям брой пъти по сравнение с прехода извън цикъла. Читателят може да си
припомни, че тази структура беше анализирана по-горе (цикъл в буферираните команди). Освен това в някои
процесори са реализирани машинни команди за условен преход, чието
предназначение е точно такова, което означава, че то може да бъде разпознато по
кода на операцията. Този трети по ред подход обикновено се реализира въз основа
на следното правило:
·
Ако преходът, указан в командата за условен преход, е назад, то той
се приема за винаги изпълнен;
·
Ако преходът е напред, то той се приема за винаги неизпълнен.
По-горе вече обяснихме, че посоката на прехода може да се определя спри сравнение с текущия адрес.
Динамическите
алгоритми за предсказване на прехода се наричат така, защото те се
основават на някаква информация за предисторията на хода на изчислителния
процес, която се опитват да използват така, че да изберат с по-голяма
вероятност реалния преход (прехода, който наистина ще се реализира). Разбира се
никаква информация не е в състояние да предскаже на 100% събития, които ще се
случат в бъдеще време. Тук искаме да поясним, че всяка команда за условен
преход описва два възможни прехода. Тук обаче става дума само за прехода по
адреса, който е указан в самата команда. Той е единствен, тъй като се
подразбира естественият метод за адресиране на командите. В глава 5-та на тази
книга ние пояснихме, че в тези условия, всички команди за управление на прехода
имат едноадресна структура.
Ще се спрем най-напред на алгоритъм, използващ двузначен (1-битов) признак (Predict). Двузначният признак характеризира чрез своите състояния командата за условен преход по следния начин:
ГВПр: голяма
вероятност за преход (Predict =
1);
МВПр: малка
вероятност за преход (Predict =
0).
Алгоритъмът
изразява функционирането на краен автомат с две състояния – ГВПр и МВПр, както
е показано на следващата фигура.
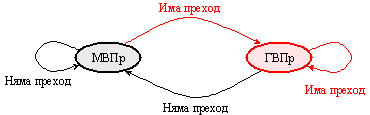
Фиг. 6.3.1.9. Алгоритъм за предсказване на прехода с двузначен признак
Нека приемем,
че началното състояние на автомата е МВПр (Predict=0). Ако командата за
условен преход реализира прехода, автоматът се превключва в състояние ГВПр (Predict=1),
в противен случай съхранява изходното състояние. Ако същата команда се срещне
още веднъж, то ще бъде предсказан онзи преход, който съответства на състоянието
на автомата. С други думи състоянието на автомата винаги съответства на
последния реален преход. При тази логика за предсказване, ако с тази команда за
условен преход е организиран цикъл, грешни предсказания на прехода ще има само
в две от срещите с нея – в първия случай, когато се предполага преход към
следващия по ред адрес, а се изпълни преход към входната точка на цикъла и
втория случай, когато се предсказва преход към входната точка на цикъла, а се
изпълни преход към следващия по ред адрес, при излизане от цикъла.
За реализиране на описания алгоритъм в апаратната част на буфера се реализира отделна (допълнителна) памет (таблица). В тази таблица временно се съхраняват всички вече изпълнени команди за условен преход. Ако в основния буфер, в резултат на предварителното извличане, бъде заредена команда за условен преход, при нейния предварителен анализ се проверява дали тя не е вече фиксирана в таблицата. Ако командата е била вече изпълнявана, то и признакът на извършения преход е бил установен в съответното състояние. Сега, при повторната й среща, напомпването на основния буфер следва да се извърши според логиката на предсказването. А тя, според автомата от фигура 6.3.1.8, е следната:
·
Ако признакът на командата в
таблицата за предсказване е в състояние МВПр (Predict=0), то според това
предсказание, предварителното извличане на команди продължава от следващия по
ред адрес, т.е. според програмния брояч. След като в конвейера постъпи
командата за условен преход, и ако нейното фактическо изпълнение води към
адреса за преход, това означава, че преходът не е
бил вярно предсказан. Така
предварително извлечените и намиращи се в основния буфер команди, не са
актуални за конвейера. На признака Predict се присвоява стойност
единица, т.е. Predict:=1 и автоматът се превключва в противоположното
състояние ГВПр.
·
Ако признакът на командата в
таблицата за предсказване е в състояние МВПр (Predict=0), то според това
предсказание, предварителното извличане на команди продължава от следващия по
ред адрес, т.е. според програмния брояч. След като в конвейера постъпи
командата за условен преход, и ако нейното фактическо изпълнение води към
следващия по ред адрес, това означава, че преходът е
бил вярно предсказан. Така
предварително извлечените и намиращи се в основния буфер команди, са актуални
за конвейера. На признака Predict се присвоява стойност нула, т.е. Predict:=0
и автоматът запазва състоянието си.
·
Ако признакът на командата в
таблицата за предсказване е в състояние ГВПр (Predict=1), то според това
предсказание, предварителното извличане на команди продължава по адреса за
преход. След като в конвейера постъпи командата за условен преход, и ако
нейното фактическо изпълнение води към адреса за преход, това означава, че
преходът е бил вярно предсказан. Така предварително извлечените и намиращи се
в основния буфер команди, са актуални за конвейера. На признака Predict
се присвоява стойност единица, т.е. Predict:=1 и автоматът запазва
състоянието си.
·
Ако признакът на командата в
таблицата за предсказване е в състояние ГВПр (Predict=1), то според това
предсказание, предварителното извличане на команди продължава по адреса за
преход. След като в конвейера постъпи командата за условен преход, и ако
нейното фактическо изпълнение води към следващия по ред адрес, това означава,
че преходът не е бил вярно предсказан. Така предварително извлечените и
намиращи се в основния буфер команди, не са актуални за конвейера. На признака Predict
се присвоява стойност нула, т.е. Predict:=0 и автоматът се превключва в
противоположното състояние МВПр.
Специално искаме да отбележим факта, че предсказанието се употребява (консумира) значително по-рано във времето, спрямо присвояването на нова стойност на предсказващия признак, което става едва когато командата за условен преход се изпълни фактически.
При първа среща на командата за условен преход, тя се записва като поредна в таблицата за предсказване на преходите, където нейният признак е установен в начално състояние МВПр (Predict=0). В същност в таблицата не е необходимо да се записва цялата команда, а само нейният адрес, който служи за разпознаването й. Това определя методът за достъп в таблицата за предсказване да бъде асоциативен.
При достатъчно голям обем на таблицата за предсказване в нея могат да бъдат фиксирани достатъчно много команди за условен преход. Ако част от тях образуват множество вложени цикли, както вече пояснихме по-горе, при всеки изход от цикъл преходът ще бъде предсказван неправилно. Това ще се случва и при първо влизане в цикъла. В такива случаи честотата на неправилното предсказване ще се повиши, в резултат на което програмата няма да може да повиши своята производителност съществено. Ето защо се търси допълнително повишаване на надеждността на предсказването. Приема се предсказанието да се променя не категорично, а на степени, както е показано в долната таблица:
Таблица 6.3.1.1 Смисъл в пресказанието
|
Състояние |
Смисъл на предсказанието |
Старши признак Predict№1 |
Младши признак Predict№0 |
|
ГГВПр |
много голяма вероятност за
преход |
1 |
1 |
|
ГВПр |
голяма вероятност за преход |
1 |
0 |
|
МВПр |
малка вероятност за преход |
0 |
1 |
|
ММВПр |
много малка вероятност за
преход |
0 |
0 |
От таблицата
се вижда, че са въведени два предсказващи признака. Логиката на алгоритъма за
предсказване се състои в изказването – “прогнозира се преход, ако последните
две реализации на командата за условен преход са реализирали преход по адреса
за преход”.
Както и в предидущия случай, логиката за предсказване се илюстрира чрез граф схемата на преходите в един краен автомат с 4 състояния, представена на фигура 6.3.1.10.
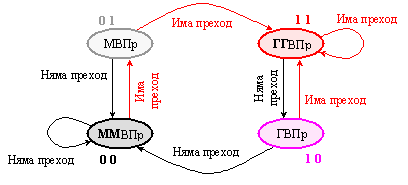
Фиг. 6.3.1.10. Алгоритъм за предсказване на прехода с 4-значен признак
След няколко
успешни предсказания “няма преход” автоматът се оказва в
състояние (00). В това състояние следващата прогноза винаги е “няма преход”.
Ако това предсказание се окаже погрешно и реалното събитие е “има преход”,
автоматът се превключва в състояние (01), но продължава да предсказва че “няма
преход”. Само ако и това предсказание се окаже погрешно, автоматът се
превключва в състояние (11), в което винаги предсказва “има преход”.
Така състоянието (11), както и състоянието (00) едно друго се постигат след
две еднакви поредни предсказания. Според описаната логика левият признак (Predict№1)
може да се интерпретира като прогноза, а десният признак (Predict№0) –
какво е било направено предидущия път, т.е. бил ли е изпълнен преходът.
Специално трябва да подчертаем, че началното (изходното) състояние на автомата от горната фигура е МВПр, т.е. (01). По аналогия могат да се разработят алгоритми с 4 или 8 признака.
При използване на информацията за предисторията на преходите, за да се облекчи преходът, освен адреса на командата, в таблицата може да се съхрани и адресът за преход (операнд на командата). Под облекчение се има предвид спестяването за в бъдеще на действията, които са необходими за изчисляване на действителната му стойност, когато той не е указан явно в адресната част на командата. Предсказанията ще бъдат ефективни само ако командата, която получава управлението според адреса за преход, бъде извлечена веднага след като бъде направено предсказанието. Ето защо е желателно предисторията да съхранява информация не само за самия преход (чрез превключване на признаците), но и за адреса на прехода. За целта структурата на таблицата за предсказване се обогатява с допълнителни структурни елементи, както е показано на фигура 6.3.1.11.
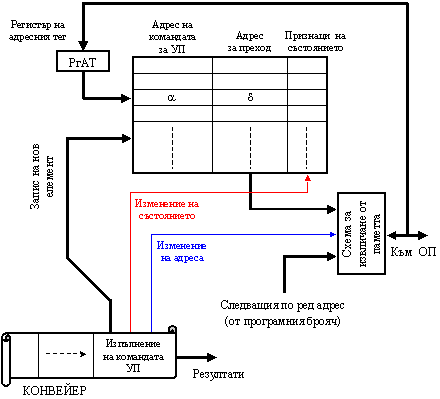
Фиг. 6.3.1.11. Таблица за динамично предсказване (със съхранена предистория
на прехода)
Както може да се види на горната фигура, предсказващата таблица има
структурата на асоциативна кеш памет. Ако поредната команда, която се зарежда в
конвейера, се окаже команда за условен преход, с нейния адрес се извършва
асоциативно претърсване на таблицата за предсказване. Ако се окаже, че той не
се съдържа в нея, т.е. командата не се е срещала в хода на програмата досега,
той, заедно с адреса за преход, се записва в нея. Ако няма свободна клетка се
избира такава, която се освобождава за данните на командата. Признаците й се
установяват в начално състояние, както вече пояснихме, а извличането на команди
продължава по естествения ред на адресите.
Ако
адресът на командата се намери в таблицата за предсказване, извличането
продължава според предсказанието на нейните признаци, както пояснихме по-горе.
Фактическото
изпълнение на заредената в конвейера команда за условен преход се осъществява
няколко такта по-късно в последното ниво на конвейера. Там се намират необходимите
схеми за манипулиране на съответната клетка в таблицата за предсказване, а
именно за установяване на новото състояние, за четене/записване на адреса за
преход и управление на следващото извличане, според новото предсказание.
Изложените по горе алгоритми за буфериране на машинните
команди не са единствените. В съвременните процесори те се реализират в
различни комбинации и модификации, при което се отчита цяла съвкупност от
фактори, отнасящи се до общата архитектура на операционната част на процесора.
За в бъдеще е възможна появата и на други алгоритми и технически решения. Това
означава, че нашата работа по представената тук тема, не е приключила, което се
отнася и за всеки читател. В следващия раздел на тази книга ще поясним някои
нови концепции в кеширането (буферирането).
Следващият
раздел е:
6.3.2. Кеш памет
(буфериране на данни)